
現在、YoloV5でトレーニングしたAIモデルをSwiftの MLモデルに変換してiOS上でアプリを作成しようと考えています。
その第一段階として新たなYolov5モデルを作成していますが、nc(カテゴリー数)が80(yolov5xのデフォルト値)よりも大きく、trainingのバッチ数等を小さくしてもGPU(Tesla 16GiB)で「CUDA Out of Memory 」エラーが出てtrainingができませんでした。
Epoch gpu_mem box obj cls total targets img_size
3/49 13.6G 0.05327 0.1503 0.07817 0.2817 637 416: 100% 11/11 [00:03<00:00, 3.59it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 33% 1/3 [00:01<00:02, 1.18s/it]tcmalloc: large alloc 6470189056 bytes == 0x7fd61db3c000 @ 0x7fe10eb11b6b 0x7fe10eb31379 0x7fe0b358774e 0x7fe0b35897b6 0x7fe0edff3d53 0x7fe0ed9de8cf 0x7fe0edcf5cac 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ef29cd6e 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ed9cc910 0x7fe0edf453f3 0x7fe0ed549a68 0x7fe0edcc7643 0x7fe0edfc5ff9 0x7fe0a5408f2e 0x7fe0a53aa367 0x7fe0efb097c2 0x7fe0efb04df9 0x7fe0fde1830d 0x7fe0fddf0524
Class Images Targets P R mAP@.5 mAP@.5:.95: 67% 2/3 [00:05<00:02, 2.05s/it]tcmalloc: large alloc 7156391936 bytes == 0x7fd2bdc40000 @ 0x7fe10eb11b6b 0x7fe10eb31379 0x7fe0b358774e 0x7fe0b35897b6 0x7fe0edff3d53 0x7fe0ed9de8cf 0x7fe0edcf5cac 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ef29cd6e 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ed9cc910 0x7fe0edf453f3 0x7fe0ed549a68 0x7fe0edcc7643 0x7fe0edfc5ff9 0x7fe0a5408f2e 0x7fe0a53aa367 0x7fe0efb097c2 0x7fe0efb04df9 0x7fe0fde1830d 0x7fe0fddf0524
tcmalloc: large alloc 6597992448 bytes == 0x7fd61db3c000 @ 0x7fe10eb11b6b 0x7fe10eb31379 0x7fe0b358774e 0x7fe0b35897b6 0x7fe0edff3d53 0x7fe0ed9de8cf 0x7fe0edcf5cac 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ef29cd6e 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ed9cc910 0x7fe0edf453f3 0x7fe0ed549a68 0x7fe0edcc7643 0x7fe0edfc5ff9 0x7fe0a5408f2e 0x7fe0a53aa367 0x7fe0efb097c2 0x7fe0efb04df9 0x7fe0fde1830d 0x7fe0fddf0524
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 3/3 [00:16<00:00, 5.49s/it]
all 48 3.05e+03 0.116 0.0848 0.13 0.0915
Epoch gpu_mem box obj cls total targets img_size
4/49 13.6G 0.04211 0.1611 0.06941 0.2726 510 416: 100% 11/11 [00:03<00:00, 3.61it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 67% 2/3 [00:06<00:02, 2.49s/it]tcmalloc: large alloc 7230545920 bytes == 0x7fcf5d06a000 @ 0x7fe10eb11b6b 0x7fe10eb31379 0x7fe0b358774e 0x7fe0b35897b6 0x7fe0edff3d53 0x7fe0ed9de8cf 0x7fe0edcf5cac 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ef29cd6e 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edc9bb4b 0x7fe0edca131b 0x7fe0edcc0135 0x7fe0edd8a2be 0x7fe0ed9cc910 0x7fe0edf453f3 0x7fe0ed549a68 0x7fe0edcc7643 0x7fe0edfc5ff9 0x7fe0a5408f2e 0x7fe0a53aa367 0x7fe0efb097c2 0x7fe0efb04df9 0x7fe0fde1830d 0x7fe0fddf0524
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 3/3 [00:19<00:00, 6.58s/it]
all 48 3.05e+03 0.114 0.0734 0.127 0.0873
Epoch gpu_mem box obj cls total targets img_size
5/49 13.6G 0.0478 0.1525 0.0718 0.2721 888 416: 100% 11/11 [00:03<00:00, 3.59it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 67% 2/3 [00:05<00:02, 2.56s/it]
Traceback (most recent call last):
File "train.py", line 492, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "train.py", line 343, in train
log_imgs=opt.log_imgs if wandb else 0)
File "/content/yolov5/test.py", line 120, in test
output = non_max_suppression(inf_out, conf_thres=conf_thres, iou_thres=iou_thres, labels=lb)
File "/content/yolov5/utils/general.py", line 337, in non_max_suppression
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
File "/usr/local/lib/python3.6/dist-packages/torchvision/ops/boxes.py", line 42, in nms
return torch.ops.torchvision.nms(boxes, scores, iou_threshold)
RuntimeError: CUDA out of memory. Tried to allocate 6.61 GiB (GPU 0; 15.75 GiB total capacity; 1.53 GiB already allocated; 1.76 GiB free; 12.66 GiB reserved in total by PyTorch)
このエラーに対応するため色々調べたんですが、batch数を減らしても効果がなく、いい案がありませんでした。
その後、AWSの SageMakerのg4dnインスタンスでメモリ容量の多いもの(32Gib, 64GiB, 128Gib)を試しましたがだめで、複数GPUを持つインスタンスも同じエラーが出てしまいました。
trainingを複数のGPUで分散処理して1台あたりのメモリー使用量を減らすようにPython のtraining.pyを書き換えるのも一案かもしれませんが、環境設定でそのようなGPU分散処理をするやり方は現在AWSに問い合わせしています。
結局、AWSのEC2インスタンスのp3dn.24xlargeをN.Virginiaで立ち上げてGPU1つあたりのメモリを32GiBにしてtrainingを実行するとエラーは解消できました。
参考までにそのやり方を記載しておきます。
まず、p3dn.24xlargeインスタンスはN.Virginiaでしか現在のところ実行できませんので、regionをN.Virgina(uș-east-1)にして、EC2を選択します。ただ問題は料金ですね。1時間あたり約$32かかりますので予算とご相談してから選択ください。
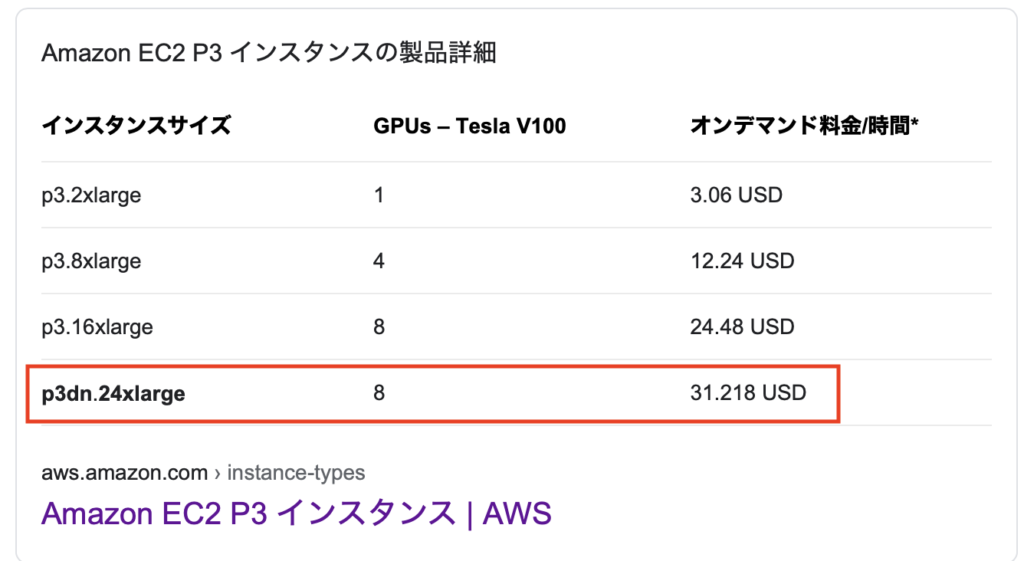
また、このEC2インスタンスはService limit increaseが必要なので、リクエストします。
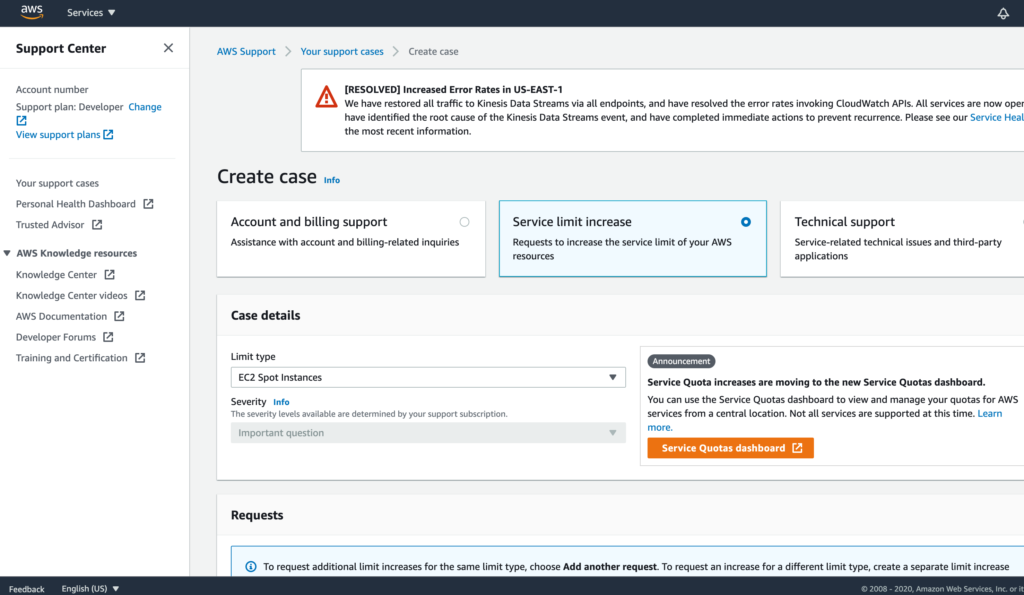
EC2インスタンスの選択で「Deep Learning AMI(Amazon Linux 2) Version 36.0(PyTorchも実装されている)」を選択します。
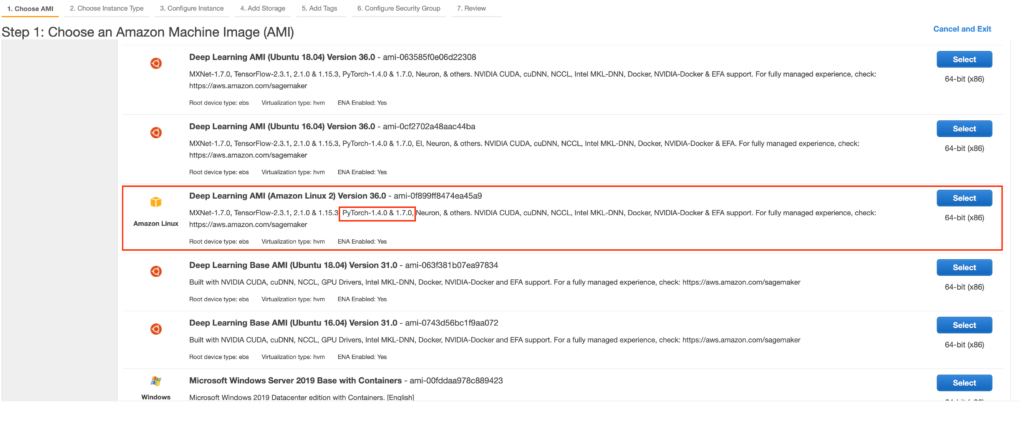
そして、インスタンスを選択します。
順次進んで、EC2インスタンスへのアクセス用のKeypairを作成してdownloadし(後にEC2とlocalのMacとでssh -i通信する際に必要)、その後Launchします。
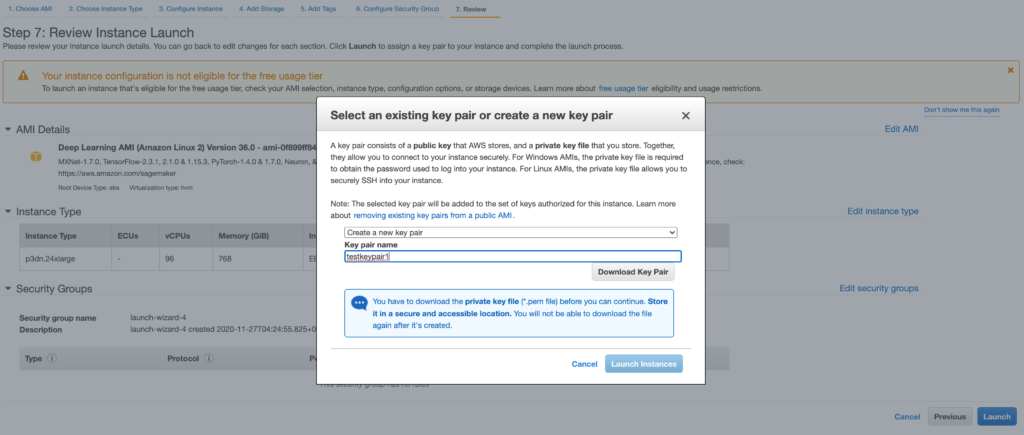
その後、DashboardでEC2インスタンスがrunningしていることを確認します(この画面ではstoppedになっています)。
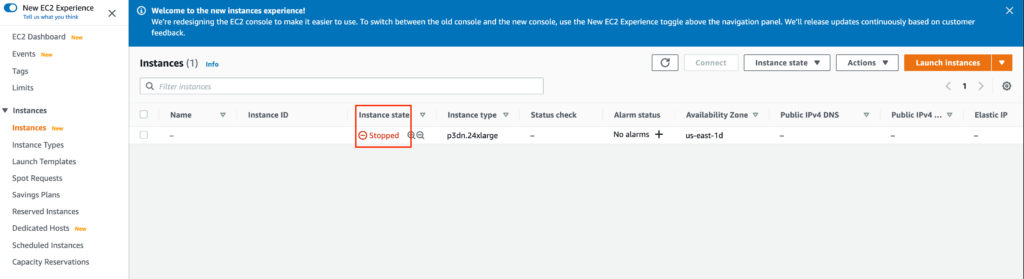
この後はMac側のterminalの操作になります。
まずは、downloadしたkeypairのpemファイルの権限を変更します(
chmod 600 test.pem
)。しないと以下のようなエラーが出ます。
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ Permissions 0644 for '/Users/tomoimacpro/AWS/pemfile/ohio_p3_8xlarge.pem' are too open. It is required that your private key files are NOT accessible by others. This private key will be ignored. Load key "/Users/tomoimacpro/AWS/pemfile/ohio_p3_8xlarge.pem": bad permissions
そして、sshでEC2インスタンスへログインします。この時、Amazon側のアドレスの設定方法につまづきました、、、、、
アクセスに使うアドレスはEC2インスタンスの設定から得ることができます。Connectを押して、その表示中の「Example」にアクセスするアドレスがあります。ただし、@の前を「ec2-user」に変更します。そしてssh -iコマンドを実行します。
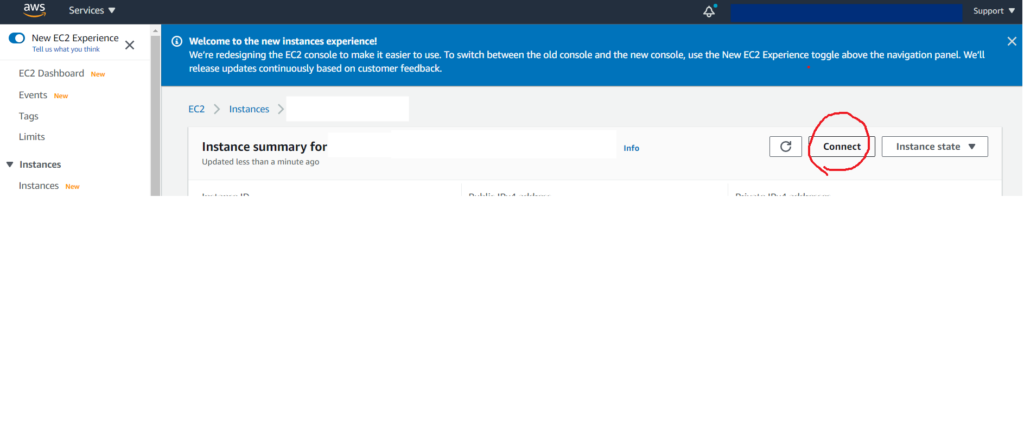
tomoimacpro@shishidotomoyukinoiMac-puro .ssh % ssh -i /Users/tomoimacpro/AWS/pemfile/virginiap3dn24xlarge.pem ec2-user@ec2-xx-xxx-xxx-xxx.compute-1.amazonaws.com
xx-xxx-xxx-xxxは上記アクセス場所を参照
=============================================================================
__| __|_ )
_| ( / Deep Learning AMI (Amazon Linux) Version 36.0
___|\___|___|
=============================================================================
Please use one of the following commands to start the required environment with the framework of your choice:
for MXNet 1.6 (+Keras2) with Python3 (CUDA 10.1 and Intel MKL-DNN) _______________________________ source activate mxnet_p36
for MXNet 1.6 (+Keras2) with Python2 (CUDA 10.1 and Intel MKL-DNN) _______________________________ source activate mxnet_p27
for MXNet 1.7 (+Keras2) with Python3 (CUDA 10.1 and Intel MKL-DNN) ________________________ source activate mxnet_latest_p37
for MXNet(+Amazon Elastic Inference) with Python3 _______________________________________ source activate amazonei_mxnet_p36
for MXNet(+Amazon Elastic Inference) with Python2 _______________________________________ source activate amazonei_mxnet_p27
for TensorFlow(+Keras2) with Python3 (CUDA 10.0 and Intel MKL-DNN) __________________________ source activate tensorflow_p36
for TensorFlow(+Keras2) with Python2 (CUDA 10.0 and Intel MKL-DNN) __________________________ source activate tensorflow_p27
for Tensorflow(+Amazon Elastic Inference) with Python2 _____________________________ source activate amazonei_tensorflow_p27
for Tensorflow(+Amazon Elastic Inference) with Python3 _____________________________ source activate amazonei_tensorflow_p36
for TensorFlow 2(+Keras2) with Python3 (CUDA 10.1 and Intel MKL-DNN) _______________________ source activate tensorflow2_p36
for TensorFlow 2(+Keras2) with Python2 (CUDA 10.1 and Intel MKL-DNN) _______________________ source activate tensorflow2_p27
for TensorFlow 2.3 with Python3.7 (CUDA 11.0 and Intel MKL-DNN) _____________________ source activate tensorflow2_latest_p37
for TensorFlow 2(+Amazon Elastic Inference) with Python3 __________________________ source activate amazonei_tensorflow2_p36
for TensorFlow 2(+Amazon Elastic Inference) with Python2 __________________________ source activate amazonei_tensorflow2_p27
for PyTorch 1.4 with Python3 (CUDA 10.1 and Intel MKL) _________________________________________ source activate pytorch_p36
for PyTorch 1.4 with Python2 (CUDA 10.1 and Intel MKL) _________________________________________ source activate pytorch_p27
for PyTorch 1.7 with Python3 (CUDA 10.1 and Intel MKL) __________________________________ source activate pytorch_latest_p36
for PyTorch(+Amazon Elastic Inference) with Python3 ___________________________________ source activate amazonei_pytorch_p36
for Chainer with Python2 (CUDA 10.0 and Intel iDeep) ___________________________________________ source activate chainer_p27
for Chainer with Python3 (CUDA 10.0 and Intel iDeep) ___________________________________________ source activate chainer_p36
for base Python2 (CUDA 10.0) _______________________________________________________________________ source activate python2
for base Python3 (CUDA 10.0) _______________________________________________________________________ source activate python3
To automatically activate base conda environment upon login, run: 'conda config --set auto_activate_base true'
Official Conda User Guide: https://docs.conda.io/projects/conda/en/latest/user-guide/
AWS Deep Learning AMI Homepage: https://aws.amazon.com/machine-learning/amis/
Developer Guide and Release Notes: https://docs.aws.amazon.com/dlami/latest/devguide/what-is-dlami.html
Support: https://forums.aws.amazon.com/forum.jspa?forumID=263
For a fully managed experience, check out Amazon SageMaker at https://aws.amazon.com/sagemaker
=============================================================================
9 package(s) needed for security, out of 12 available
Run "sudo yum update" to apply all updates.
[ec2-user@ip-xxx-xx-x-xx ~]$
ここでColabと同じようにyolov5をgit cloneでコピーして適宜設定(例、./yolov5/requirements.txtのpipインストール、training data等のzip展開、yolov5x.yamlファイルのncの書き換え)を行います。
EC2インスタンスとのファイルのやりとりはscp -iコマンドでMacのterminalから実行します。例えばこんな感じですね。
tomoimacpro@shishidotomoyukinoiMac-puro ~ % scp -i /Users/tomoimacpro/AWS/pemfile/virginiap3dn24xlarge.pem /Users/tomoimacpro/Yolov5/notesdata/Notes4v1.zip ec2-user@ec2-xx-xxx-xxx-xxx.compute-1.amazonaws.com:/home/ec2-user/ トレーニングの結果のfolderごとlocalのMacへと転送する場合 tomoimacpro@shishidotomoyukinoiMac-puro ~ % scp -i /Users/tomoimacpro/AWS/pemfile/virginiap3dn24xlarge.pem -r ec2-user@ec2-xx-xxx-xxx-xxx.compute-1.amazonaws.com:/home/ec2-user/yolov5/runs/train/exp2/ ./exp2
上記のような感じでEC2内でyolov5の実行環境ができたらtrainingを実行します。結果はこんな感じでした。
[ec2-user@ip-172-31-8-22 yolov5]$ python train.py --img 416 --batch 16 --epochs 700 --data ../data.yaml --cfg ./models/yolov5x.yaml --weights ../last11.pt --nosave --cache
Using torch 1.7.0 CUDA:0 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:1 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:2 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:3 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:4 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:5 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:6 (Tesla V100-SXM2-32GB, 32510MB)
CUDA:7 (Tesla V100-SXM2-32GB, 32510MB)
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5x.yaml', data='../data.yaml', device='', epochs=700, evolve=False, exist_ok=False, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[416, 416], local_rank=-1, log_imgs=16, multi_scale=False, name='exp', noautoanchor=False, nosave=True, notest=False, project='runs/train', rect=False, resume=False, save_dir='runs/train/exp2', single_cls=False, sync_bn=False, total_batch_size=16, weights='../last11.pt', workers=8, world_size=1)
Start Tensorboard with "tensorboard --logdir runs/train", view at http://localhost:6006/
Hyperparameters {'lr0': 0.01, 'lrf': 0.2, 'momentum': 0.937, 'weight_decay': 0.0005, 'warmup_epochs': 3.0, 'warmup_momentum': 0.8, 'warmup_bias_lr': 0.1, 'box': 0.05, 'cls': 0.5, 'cls_pw': 1.0, 'obj': 1.0, 'obj_pw': 1.0, 'iou_t': 0.2, 'anchor_t': 4.0, 'fl_gamma': 0.0, 'hsv_h': 0.015, 'hsv_s': 0.7, 'hsv_v': 0.4, 'degrees': 0.0, 'translate': 0.1, 'scale': 0.5, 'shear': 0.0, 'perspective': 0.0, 'flipud': 0.0, 'fliplr': 0.5, 'mosaic': 1.0, 'mixup': 0.0}
from n params module arguments
0 -1 1 8800 models.common.Focus [3, 80, 3]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 1 315680 models.common.BottleneckCSP [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 1 3311680 models.common.BottleneckCSP [320, 320, 12]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 1 13228160 models.common.BottleneckCSP [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 1 4099840 models.common.SPP [1280, 1280, [5, 9, 13]]
9 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 5435520 models.common.BottleneckCSP [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 1360960 models.common.BottleneckCSP [640, 320, 4, False]
18 -1 1 922240 models.common.Conv [320, 320, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 5025920 models.common.BottleneckCSP [640, 640, 4, False]
21 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
24 [17, 20, 23] 1 2234028 models.yolo.Detect [327, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [320, 640, 1280]]
Model Summary: 607 layers, 90627308 parameters, 90627308 gradients
Transferred 800/802 items from ../last11.pt
Optimizer groups: 134 .bias, 142 conv.weight, 131 other
Scanning '../train/labels.cache' for images and labels... 193 found, 0 missing, 0 empty, 23 corrupted: 100%|█████████████████████████████████████████████████████████████████████| 192/192 [00:00<00:00, 916161.97it/s]
Caching images (0.1GB): 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 170/170 [00:00<00:00, 3656.57it/s]
Scanning '../valid/labels.cache' for images and labels... 55 found, 0 missing, 0 empty, 7 corrupted: 100%|█████████████████████████████████████████████████████████████████████████| 54/54 [00:00<00:00, 464123.80it/s]
Caching images (0.0GB): 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 3320.30it/s]
Analyzing anchors... anchors/target = 2.75, Best Possible Recall (BPR) = 0.9997
Image sizes 416 train, 416 test
Using 8 dataloader workers
Logging results to runs/train/exp2
Starting training for 700 epochs...
Epoch gpu_mem box obj cls total targets img_size
0/699 2.92G 0.04909 0.164 0.07155 0.2847 645 416: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:35<00:00, 3.26s/it]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.33it/s]
all 48 3.05e+03 0.00218 0.00123 0.00209 0.000422
Epoch gpu_mem box obj cls total targets img_size
1/699 13.5G 0.04577 0.1529 0.06852 0.2672 689 416: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:07<00:00, 1.52it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:12<00:00, 4.08s/it]
all 48 3.05e+03 0.052 0.011 0.0431 0.0151
6 -1 1 13228160 models.common.BottleneckCSP [640, 640, 12]
7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2]
8 -1 1 4099840 models.common.SPP [1280, 1280, [5, 9, 13]]
9 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
10 -1 1 820480 models.common.Conv [1280, 640, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 5435520 models.common.BottleneckCSP [1280, 640, 4, False]
14 -1 1 205440 models.common.Conv [640, 320, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 1360960 models.common.BottleneckCSP [640, 320, 4, False]
18 -1 1 922240 models.common.Conv [320, 320, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 5025920 models.common.BottleneckCSP [640, 640, 4, False]
21 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False]
24 [17, 20, 23] 1 2234028 models.yolo.Detect [327, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [320, 640, 1280]]
Model Summary: 607 layers, 90627308 parameters, 90627308 gradients
Epoch gpu_mem box obj cls total targets img_size
697/699 13.5G 0.03745 0.1252 0.02247 0.1851 301 416: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:05<00:00, 2.14it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:13<00:00, 4.55s/it]
all 48 3.05e+03 0.48 0.754 0.803 0.651
Epoch gpu_mem box obj cls total targets img_size
698/699 13.5G 0.03707 0.1258 0.02239 0.1852 772 416: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:05<00:00, 2.20it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:14<00:00, 4.71s/it]
all 48 3.05e+03 0.477 0.754 0.807 0.661
Epoch gpu_mem box obj cls total targets img_size
699/699 13.5G 0.04213 0.1422 0.02248 0.2068 455 416: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:05<00:00, 2.18it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:22<00:00, 7.49s/it]
Note: detected 96 virtual cores but NumExpr set to maximum of 64, check "NUMEXPR_MAX_THREADS" environment variable.
Note: NumExpr detected 96 cores but "NUMEXPR_MAX_THREADS" not set, so enforcing safe limit of 8.
NumExpr defaulting to 8 threads.
all 48 3.05e+03 0.479 0.754 0.807 0.661
Optimizer stripped from runs/train/exp2/weights/last.pt, 181.8MB
700 epochs completed in 4.109 hours.
この場合700epochsを約4時間掛けてmAP@.5(認識精度)が約0.8程度のtrainingができました。
まあコストと相談して実施ですかね、、、、
コメント