
前回の多言語化その6では、「日本語音声解析」の具体例を紹介しました。今日は「英語」と「ドイツ語」の音声解析のSwiftUIプログラミングをご紹介します。英語はこんな感じです。

では、コードの準備です。まず、その5の手順の様にInfo.plistを編集します。「+」ボタンを押して、「Privacy Microphone Usage Description」と「Privacy Speech Recognition Usage」のValueに何か文言を適当に入れます。
次に、ContentView.swiftにコードを貼り付けます(ここまでは同じですので、「日本語音声解析」を試した人は同じもので大丈夫です。
そして、SpeechAnalyzer.swiftを編集します。以下のコードを張り替えてください。違う部分をその後説明します。
//
// SpeechAnalyzer.swift
// SpeechAnalyzer1
//
// Created by 宍戸知行 on 2020/03/24.
// Copyright © 2020 宍戸知行. All rights reserved.
//
import Foundation
import Combine
import AVFoundation
import Speech
import NaturalLanguage
final class SpeechAnalyzer: ObservableObject {
// @State private var player: AVAudioPlayer?
//localeは、ja-JP, en-US, de-DE
private var speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "en-US"))!
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private var recognitionTask: SFSpeechRecognitionTask?
private let audioEngine = AVAudioEngine()
@Published var text: String = NSLocalizedString("解析を開始します", comment: "Start Analysis")
@Published var recordingControl: Bool = false
//テキスト処理用の変数
var words = [String]()
@Published var selectedWords = [String]()
let tagger = NLTagger(tagSchemes: [.lexicalClass, .language])
let options: NLTagger.Options = [.omitPunctuation, .omitWhitespace]
func micButtonTapped(){
//wordsとselectedWordsも初期化
self.words = [String]()
self.selectedWords = [String]()
//recordingの状態に合わせて処理
if audioEngine.isRunning {
// 音声エンジン動作中なら停止
audioEngine.stop()
recognitionRequest?.endAudio()
recordingControl = false
//audioをplaysessionに戻す
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setCategory(AVAudioSession.Category.playback)
try audioSession.setMode(AVAudioSession.Mode.default)
} catch{
print("audio session error")
}
return
}
// 録音を開始する
try! startRecording()
recordingControl = true
}
func startRecording() throws {
//英語の時の処理(ドイツ語のときはde-DEに変更する
self.speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "en-US"))!
// Cancel the previous task if it's running.
recognitionTask?.cancel()
self.recognitionTask = nil
// Configure the audio session for the app.
let audioSession = AVAudioSession.sharedInstance()
try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
let inputNode = audioEngine.inputNode
//After test == "" at the previous recognition session, the speech recognition did not function.
// self.audioEngine.stop()
// try self.audioEngine.start()
inputNode.removeTap(onBus: 0) //this can avoid the following error:Terminating app due to uncaught exception 'com.apple.coreaudio.avfaudio', reason: 'required condition is false: _recordingTap == nil'
self.recognitionTask = SFSpeechRecognitionTask()
self.text = NSLocalizedString("解析中です", comment: "Being analyzed")
// Create and configure the speech recognition request.
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
guard let recognitionRequest = recognitionRequest else { fatalError("Unable to create a SFSpeechAudioBufferRecognitionRequest object") }
recognitionRequest.shouldReportPartialResults = true
// Keep speech recognition data on device
if #available(iOS 13, *) {
recognitionRequest.requiresOnDeviceRecognition = false
}
// Create a recognition task for the speech recognition session.
// Keep a reference to the task so that it can be canceled.
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { result, error in
var isFinal = false
if let result = result {
// ***We will update State here!***
// ??? = result.bestTranscription.formattedString
isFinal = result.isFinal
self.text = result.bestTranscription.formattedString
print("Text \(result.bestTranscription.formattedString)")
}
//error処理と先にtext=""を処理する:textはoptionalではないがnullが代入されているようなので処理を中断することにする
guard error == nil else {
print ("RecognitionTaskにError(\(String(describing: error)))がでました。")
/* Error Domain=kAFAssistantErrorDomain Code=209 “(null)”エラー解決法*/
self.recognitionTask?.cancel()
self.recognitionTask?.finish()
return
}
if isFinal { //if error != nil || isFinal
//先にrecognition task を止める
self.recognitionRequest = nil
self.recognitionTask = nil
//次にaudioEngineを止める
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
print("error != nil || isFinal通過後のtextは(\(self.text))です。")
//textに文字列が入っていれば入力文書を解析してWordsに追加する
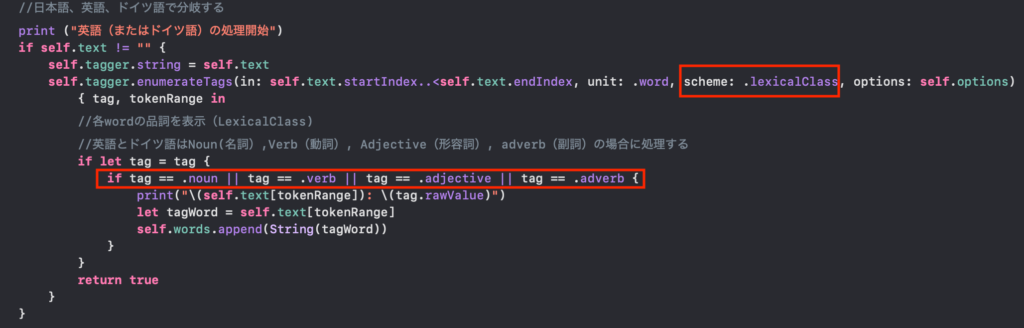
//日本語、英語、ドイツ語で分岐する
print ("英語(またはドイツ語)の処理開始")
if self.text != "" {
self.tagger.string = self.text
self.tagger.enumerateTags(in: self.text.startIndex..<self.text.endIndex, unit: .word, scheme: .lexicalClass, options: self.options) { tag, tokenRange in
//各wordの品詞を表示(LexicalClass)
//英語とドイツ語はNoun(名詞),Verb(動詞), Adjective(形容詞), adverb(副詞)の場合に処理する
if let tag = tag {
if tag == .noun || tag == .verb || tag == .adjective || tag == .adverb {
print("\(self.text[tokenRange]): \(tag.rawValue)")
let tagWord = self.text[tokenRange]
self.words.append(String(tagWord))
}
}
return true
}
}
//wordsをプリントする
print("wordsは、\(self.words)です。")
//selectedWordsに代入
self.selectedWords = self.words
//selectedWorsをプリント
print("selectedWordsは、\(self.selectedWords)です。")
//選択されたwordsでitemsをscoringしてsortingする
// self.scoring(with: self.selectedWords)
//配列をSortingする
// self.itemsForSorting.sort{$0.score > $1.score}
}
}
// Configure the microphone input.
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
try audioEngine.start()
}
}
違う部分は2箇所あります。一つ目は、”speechRecognizer”のlocaleを英語”en-US”にする部分です。
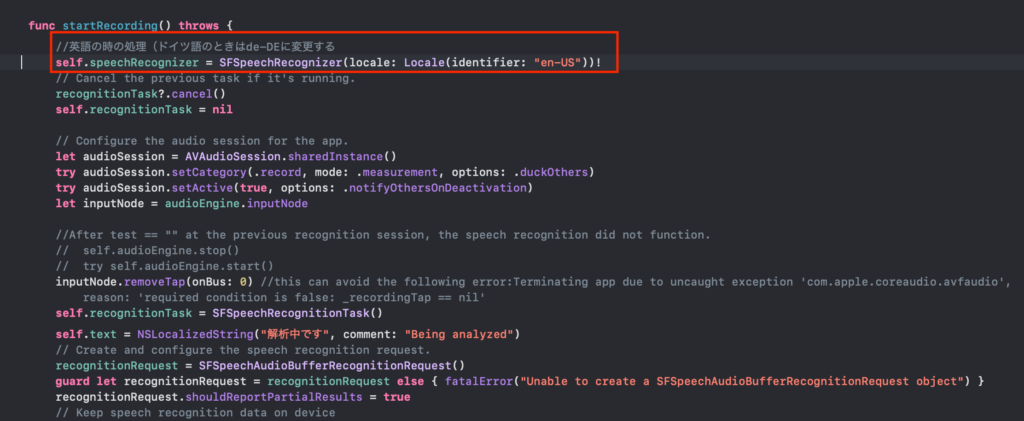
このLocaleのidentifierを使用する言語に合わせて切り替えます。ここに一覧がありますね。
次に英語とドイツ語の認識したWordsの処理については、日本語のものとは違います。日本語では認識したWordsからひらがな1文字と2文字を除外する手法を採用してselectedWordsを選別しました。英語とドイツ語では、taggerが品詞まで判別してくれるので、「動詞(Verb)」「名詞(Noun)」「形容詞(Adjective)」「副詞(Adverb)」に分解して選別することにしました(冠詞と前置詞を除きました)。やり方は、taggerのschemeに「.lexicalClass」を指定して品詞まで分解する方式にします。そして、得られたtagが「.noun/.verb/.adjective/.adverb」のいずれかである場合(||で結ぶ)にWordsに追加するようにプログラミングしました。
上記のgif動画でのdebuggerの解析画面を示します。
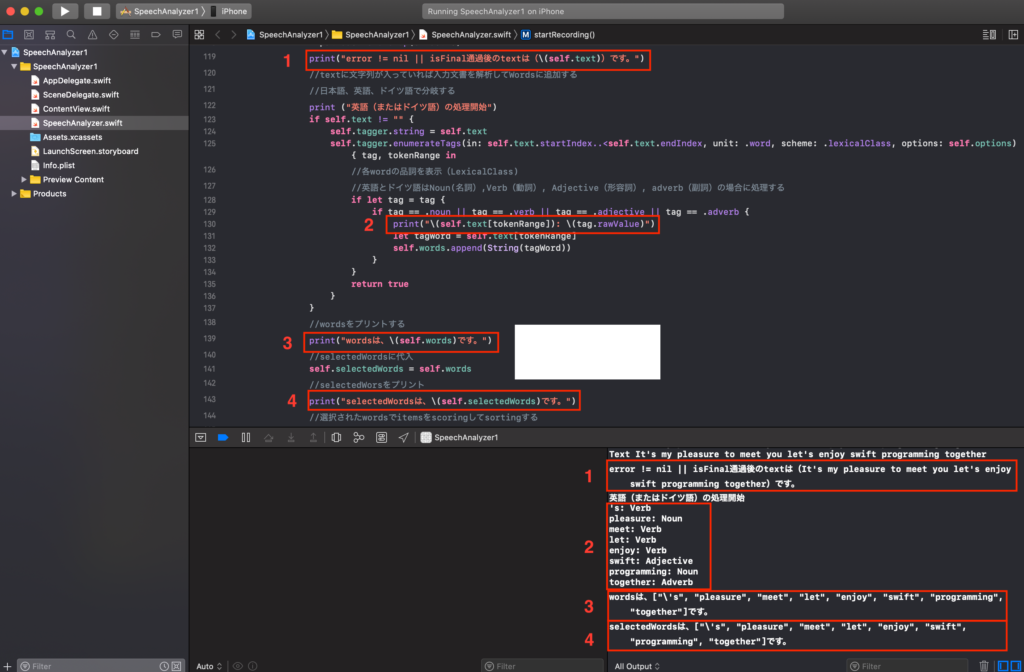
1で得られたtext、2で個々のWordと品詞、3で[word]の中身、4で選別したselectedWordsを示しています。
この様にして得られたselectedWordsをヘルパーKでは各メニューに対して、タイトルや中身の文言にヒットするかどうかでscoringし、その優先順位にしたがってメニューを表示するアルゴリズムにしています。また、selectedWordsがkeywordに当てはまるかどうかを判定し、keywordに従って適宜音声出力(英語とドイツ語で)するようにプログラミングしました。
では、ドイツ語の場合を説明します。上との違いはたった1箇所です。speechRecognizerのlocaleを変更するだけです。

では、実際にアプリを動かして簡単なドイツ語会話を解析してみましょう!

DebuggerのDebug画面を見てみましょう。
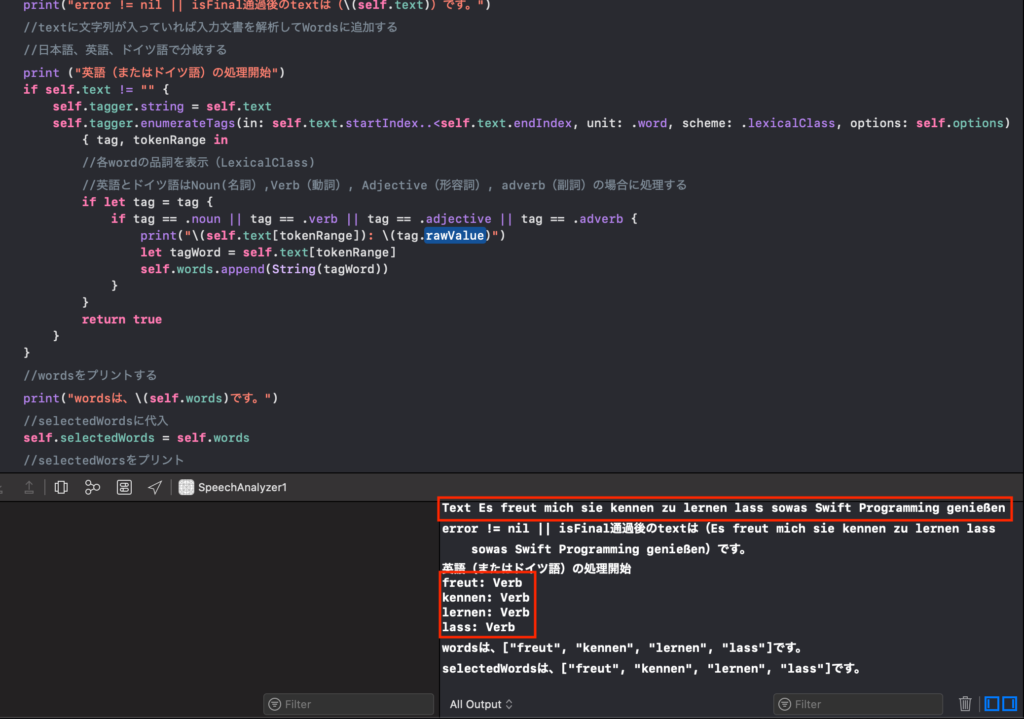
どうやらドイツ語では名詞(Noun)が認識されないようですね、認識するものとしないものがあるようです。動詞がいくつか出ていますが、最後の(genisen)は認識されておらず、英語に比べると品詞の分解能は限定されているようです(日本語はもともと品詞分解機能はいまのところないです)。このようにして、各言語に対応して音声解析処理を進めていくとよいと思われます。
次回はメニューアイテムをscoringするのに使用したりする多言語JSONデータの作成方法とその内容を見ていく予定にしています。
コメント